Obecnie w większości przedsiębiorstw oraz organizacji, serwery stanowią jedną z fundamentalnych części infrastruktury IT. Niezawodność oraz dostępność danych, aplikacji oraz maszyn, na których się znajdują, stanowią kluczowe role w codziennych operacjach firm. Nieprzewidywalne awarie tej części infrastruktury, mogą powodować przerwy w płynnym funkcjonowaniu środowiska oraz inne niepożądane skutki, w tym straty finansowe lub wizerunkowe.
Najpopularniejszym rozwiązaniem przeciwdziałania awariom jest stosowanie regularnie wykonywanych kopii zapasowych, które dokładnie zostały przedstawione w artykule na naszym blogu. Można je przechowywać:
- lokalnie – na zewnętrznym dysku USB, taśmach magnetycznych lub urządzeniu NAS (Network Attached Storage), często zawierającym dodatkowe zabezpieczenie przed utratą danych w postaci macierzy RAID, która zapobiega utracie danych przy ewentualnej awarii jednego z dysków
- online – dane przechowywane są na zewnętrznym serwerze – model IaaS (Infrastruktura jako Usługa), dzięki czemu są zabezpieczone przed lokalnymi awariami, a dostęp do kopii zapasowych można uzyskać niezależnie od wewnętrznej sieci firmy.
Czym jest DRP? W jakich przypadkach jest potrzebne?
Disaster Recovery Plan – Plan przywracania po awarii jest dokumentem zawierającym procedury oraz zasady postępowania, których przestrzeganie ma na celu sprawne wznowienie prawidłowego działania m.in. infrastruktury IT w przypadku niespodziewanej awarii. DRP jest częścią składową Business Continuity Planning, czyli strategii zapewnienia ciągłości działania kluczowych procesów organizacji.
Plan przywracania definiują między innymi następujące wskaźniki:
- RPO (Recovery Point Objective) – określa dopuszczalną ilość utraty danych. Jest to czas pomiędzy wystąpieniem awarii a ostatnim backupem danych. Przy założeniu ze firma akceptuje poziom RPO na poziomie 3 godzin, backup bądź replikacja danych powinna się odbywać minimum co 3 godziny.
- RTO (Recovery Time Objective) – określa maksymalny czas przywrócenia kopii zapasowej, usług lub środowiska po awarii.
DRP jest istotne w przypadku wysokiej oceny ryzyka utraty danych lub braku dostępu do infrastruktury IT. Do zagrożeń stwarzających takie ryzyko zalicza się:
- Klęski żywiołowe – powodzie, pożary, trzęsienia ziemi.
- Zagrożenia technologiczne – zakłócenia w dostawie mediów, wycieki materiałów niebezpiecznych, awarie infrastruktury IT.
- Błędy ludzkie – wycieki danych lub zagrożenia spowodowane przez człowieka, takie jak cyberataki.
Przeprowadzenie odzyskania środowiska po awarii – case study.
W dzisiejszym świecie technologicznym, gdzie firmy i organizacje coraz bardziej polegają na infrastrukturze IT, możliwość sprawnego odzyskania środowiska po awarii jest nieodzownym elementem utrzymania wydajności pracy oraz bezpieczeństwa danych.
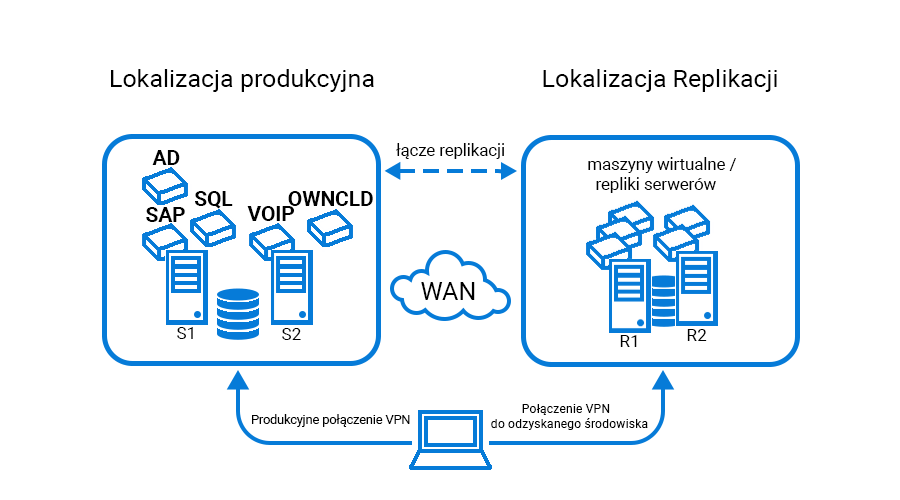
Jednym z klientów Support Online jest firma, w której wdrożona została usługa umożliwiająca odzyskanie środowiska po awarii. Usługa polega na replikacji kluczowych maszyn klienta znajdujących się w lokalnej serwerowni do oddalonego geograficznie datacenter.
Case study opisane w tym artykule przedstawia opis procesu testowego odzyskania środowiska po kontrolowanej awarii lokalnej infrastruktury IT.
Konfiguracja środowiska – kluczowe elementy do odzyskania
W biurze klienta Support Online skonfigurowane są dwie kluczowe wirtualne sieci lokalne VLAN: Jedna z nich to DMZ (demilitarized zone) – obszar sieci, oddzielony od sieci wewnętrznej, w której znajdują się serwery m.in. hostujące strony internetowe, na które prawdopodobieństwo cyberataku jest większe, dzięki czemu atakującemu uniemożliwiony jest dostęp do sieci lokalnej. Druga sieć wirtualna jest siecią wewnętrzną, w której znajduje się pozostała infrastruktura IT. Obydwie sieci muszą zostać jednakowo skonfigurowane po stronie zreplikowanego środowiska, aby odwzorować konfigurację sieciową w biurze klienta.
Serwery z biura klienta są replikowane na serwery Support Online w interwale jednogodzinnym, dzięki czemu podczas awarii w lokalnej serwerowni, istnieje możliwość przywrócenia środowiska, w stanie zgodnym ze stanem serwerów podczas wykonywania replikacji.
Istotnym elementem jest również konfiguracja połączenia VPN, które umożliwi połączenie się z uruchomionym środowiskiem zapasowym. W tym przypadku pracownicy firmy łączą się zdalnie do biura przez VPN używając aplikacji FortiClient. Na potrzeby testu rozesłaliśmy automatycznie do wszystkich pracowników drugi profil połączenia. Dzięki temu pracownicy zdalni mogą bez problemu połączyć się do środowiska zapasowego i pracować na uruchomionych tam serwerach.
Wymienione powyżej środowisko składające się z dziesięciu serwerów oraz konfiguracji sieciowej będą kluczowe dla nas do przywrócenia po niespodziewanej awarii.
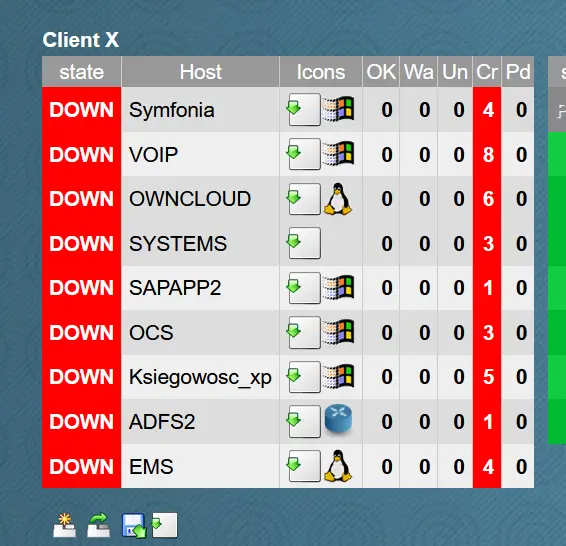
Test opisany w artykule symuluje wydarzenie, w którym uszkodzone zostały wszystkie serwery w biurze np. w przypadku pożaru serwerowni.
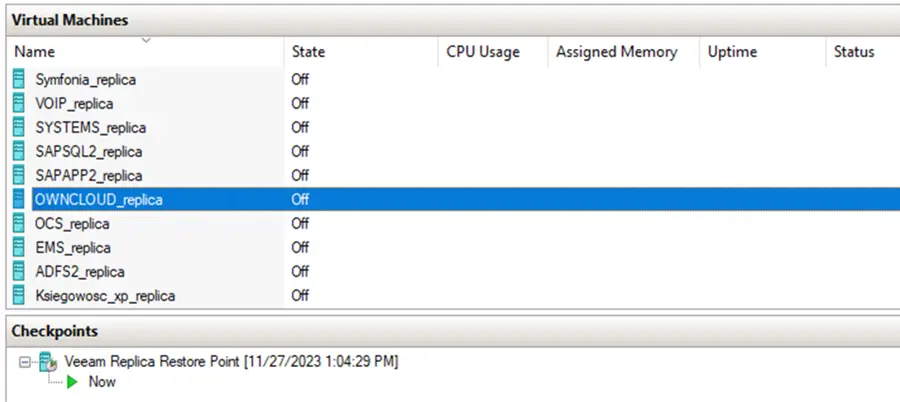
Przebieg odzyskania środowiska po awarii.
Otrzymanie informacji oraz diagnoza awarii
Pierwszym krokiem przed odzyskaniem jest informacja o niespodziewanej awarii infrastruktury IT. O przerwie w działaniu lub dostępie do serwerów jako pierwszy powiadamia monitoring Support Online, który dokładnie został przedstawiony w oddzielnym artykule opisującym ten temat, na naszym blogu. Nasi inżynierowi pracujący w trybie 24/7 potwierdzają wystąpienie awarii z osobą odpowiedzialna za autoryzacje takich zgłoszeń po stronie klienta. Kiedy wszystkie osoby biorące udział w procedurach zostały poinformowane o rozpoczęciu procedur DRP i/lub BCP, możemy przystąpić do procedury odzyskania środowiska DR.
Zatrzymanie replikacji serwerów
Wyłączenie lub zatrzymanie replikacji w oprogramowaniu do tworzenia kopii zapasowej jest następnym krokiem, który jest ważny do bezproblemowego, testowego odzyskania środowiska. Dzięki temu, po przeprowadzonym teście będziemy mogli cofnąć się do stanu pierwotnego.
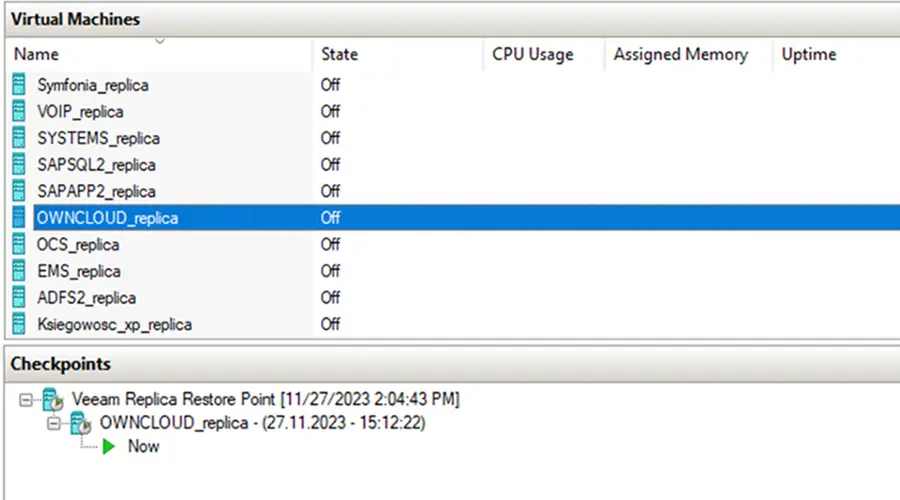
Utworzenie dodatkowego checkpointa maszyn
Wykonanie dodatkowego punktu przywracania, jest dodatkową opcją zabezpieczenia środowiska. W przypadku, gdy na odzyskanym środowisku zostaną usunięte lub utracone kluczowe dane, jest możliwość odzyskania ich poprzez przywrócenie checkpointa.
Zmiana wirtualnych kart sieciowych
Rekonfiguracja sieci następuje po wyłączeniu replikacji. Wszystkie replikowane serwery wewnątrz oprogramowania do wirtualizacji Hyper-V zostają przydzielone do odpowiedniej wirtualnej sieci lokalnej, a karty sieciowe maszyn zostają zmienione, aby odwzorować środowisko infrastruktury w firmie przed nastąpieniem awarii. Dzięki temu maszyny zostają uruchomione w odpowiednich i przydzielonych dla nich VLANach, usługi wystawione na świat pozostają wystawione tak samo jak w środowisku produkcyjnym (ewentualne zmiany musza zostać wykonane po stronie serwera DNS uwzględniając nowa/inną adresacje WAN).
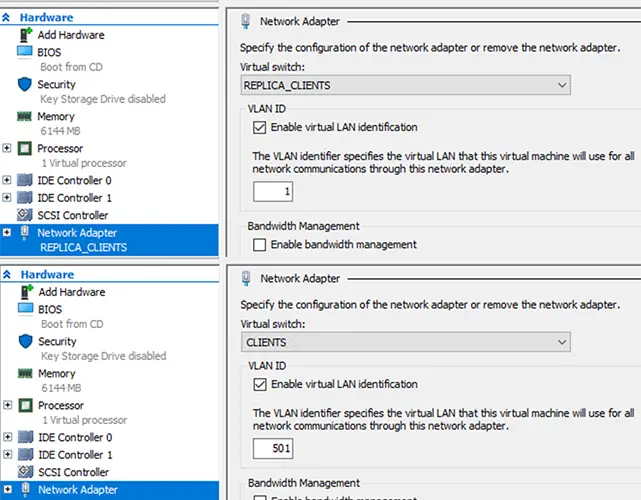
Poniżej: zmieniona karta sieciowa oraz ustawiony VLAN
Włączenie serwerów
Włączenie maszyn oraz weryfikacja prawidłowego działania są kolejnym krokiem odzyskiwania środowiska. W tym przypadku weryfikowane jest zainstalowane oprogramowanie, funkcjonalność komunikacji aplikacji pomiędzy serwerami, baz danych oraz stron WWW hostowanych na serwerach.
Podczas uruchamiania serwerów ważna jest kolejność uruchamiania maszyn. Jeżeli jedna z maszyn pełni rolę serwera DHCP, powinna ona być uruchomiona jako pierwsza, w innym wypadku serwery, które powinny otrzymać przydzielone adresy IP, mogą zmienić swoją konfigurację sieciową, przez co wymagana jest ręczna konfiguracja.
Każdy z pracowników może się połączyć poprzez zapasowy profil VPN na swoim komputerze do zapasowego środowiska i pracować na udostępnionych tam zasobach.
Poinformowanie o odzyskaniu środowiska
Ostatnim krokiem jest poinformowanie osób biorących udział w procedurach DRP o odzyskaniu oraz zweryfikowaniu prawidłowego funkcjonowania środowiska. Powyżej opisany test procedury DRP umożliwił firmie kontynuowanie pracy 30 minut od wystąpienia awarii w lokalnej serwerowni.
Podsumowanie:
DRP jest kluczowym elementem, który należy uwzględnić przy tworzeniu planu Continuity Business Planning, aby zachować płynność działania firmy oraz zminimalizować okres bezczynności po wystąpieniu niespodziewanej awarii. Aby zapewnić skuteczność planu przywracania po awarii, należy wykonywać regularne audyty, testy oraz aktualizacje procedur.
Support Online posiada wieloletnie doświadczenie w wdrażaniu rozwiązań disaster recovery (DR). W tym czasie wykonaliśmy dziesiątki testów w różnych środowiskach i wypracowaliśmy najlepsze metody. Dziś pozwalają nam one realizować podobne projekty dla firm w których bezpieczeństwo i ciągłość działania są priorytetem.


